Introducing FARS
FARS (Fully Automated Research System) is an end-to-end AI research system that operates at scale. It is designed to autonomously perform the complete research workflow—including ideation, planning, experimentation, and paper writing—without human intervention during execution. In its current instantiation, FARS is applied primarily to AI research, thereby positioning it within an emerging AI-for-AI (AI4AI) research paradigm.
Live: https://analemma.ai/fars (Starts at 10:00 PM EST, UTC−5 on February 12, 2026)
GitLab: https://gitlab.com/fars-a
Building an AI Research System from First Principles
The human-centered research ecosystem is shaped by constraints such as limited
human labor, finite attention, and institutional incentives.1.Examples of such constraints include:
- The high entry barrier to conducting research, combined with a high rate of trial-and-error failure, significantly constrains the supply of skilled researchers.
- The strong bias toward publishing only “successful” experiments, leaving many negative results unpublished and repeatedly rediscovered by different researchers.
- The treatment of each paper as a maximal unit of contribution, rather than a minimal, composable piece of knowledge. In contrast,
automated research systems built on modern LLMs offer the possibility of
relaxing many of these constraints, enabling scientific discovery to be
conducted in a more efficient, scalable, and cost-effective manner. Prior work
on automated scientific research—including systems such as
AI Scientist,
CycleResearcher,
Zochi,
AI Scientist v2,
AI Researcher, and
DeepScientist—has shown that current AI
systems are capable of conducting non-trivial research tasks in an automated or
semi-automated manner. However, these systems have not been widely deployed, and
many remain designed to produce papers that adhere to the conventions of modern
academic publishing.
Instead of optimizing for compatibility with existing academic formats, FARS is built from first principles of a research system: efficiently and reliably expand the frontier of knowledge. The output of an ideal research system is a collection of research contributions, each consisting of a clearly articulated hypothesis and its empirical or theoretical validation. As long as a hypothesis is well-motivated and informative, the outcome of its validation—whether positive or negative—constitutes meaningful knowledge and should be reported. FARS is designed to produce outputs resembling short papers: each paper is focused on a single, well-scoped contribution, may explicitly report negative results, and is not required to conform to unnecessary length or structural constraints.
A Live and Large-Scale Deployment
We plan to run the first public deployment of FARS as a live experiment. During the livestream, FARS will run continuously and autonomously until it has produced 100 complete research papers.
We chose to do this for a specific reason: scale is critical for automated research. Evaluating an AI research system based on a handful of examples is insufficient. A system like FARS produces research outputs that vary widely across topics, methods, and quality. No single team can reliably assess such a system in isolation. Meaningful evaluation requires exposure to diverse perspectives from across the academic community, spanning different fields and research traditions.
By deploying FARS at scale and making its operation observable2.FARS will use its own GitLab account for public submission during the work process., we aim to accelerate feedback from researchers, reviewers, and practitioners. We want to understand not only whether individual papers are interesting, but how a broadly deployed automated research system interacts with the norms, incentives, and dynamics of the scientific community. We also take necessary actions to ensure responsible dissemination of the system outputs.3.Before any paper is submitted to arXiv, it will be manually reviewed by at least three researchers on our team, each with more than five years of research experience. Only papers that pass this internal review will be submitted, and all submissions will be explicitly labeled as AI-generated.
Method
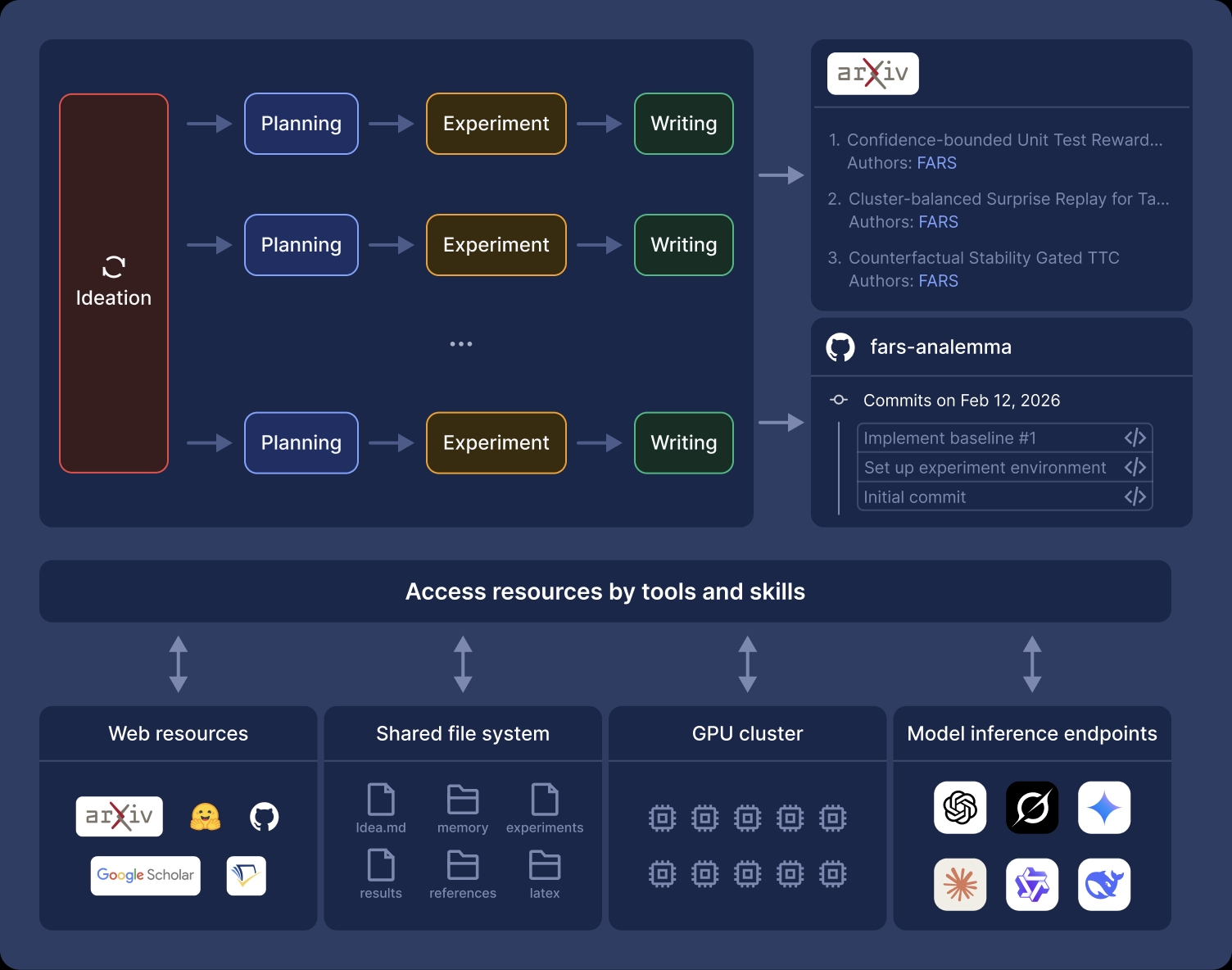
We implement FARS as a multi-agent research system composed of four specialized agents: Ideation, Planning, Experiment, and Writing.
The Ideation agent takes as input a document specifying multiple research directions, conducts literature review and generates research hypotheses given access to open-access papers and public GitLab repositories. Each hypothesis that passes automated review is sequentially forwarded to the planning, experiment, and writing agents, resulting in a complete research paper. In this deployment, we suggest FARS to start with the following topics but it is also encouraged to explore any other topics freely.
Reinforcement Learning from Verifiable Rewards
Reinforcement Learning from Verifiable Rewards (RLVR) is a paradigm for training Large Language Models (LLMs) where the reward signal comes from programmatically verifiable outcomes rather than learned reward models or human preferences.
All agents collaborate through a shared file system, which serves simultaneously as a workspace and a persistent memory. For each long-horizon research task, agents read from and write to structured project directories. This shared workspace enables coordination across stages without requiring direct agent-to-agent communication, and allows the system to scale to many concurrent research projects.
To support experimentation at scale, we encapsulate a GPU cluster consisting of 160 NVIDIA GPUs as training and inference tools accessible to the experiment agent. This allows the system to efficiently schedule and manage computational workloads, while isolating the agents from low-level infrastructure concerns that are not directly relevant to research. In addition, the experiment agent is granted access to a broad range of commonly used model inference endpoints, which enables experiments such as data synthesis, agent design and LLM-as-a-Judge, etc.
Limitations
As an early-stage automated research system, FARS has several important limitations.
- Domain scope. At present, FARS is primarily applied to research in artificial intelligence, particularly large language models. This reflects its current role as an AI-for-AI (AI4AI) system, rather than a fundamental limitation of the underlying approach.
- Resource and interaction constraints. Due to practical resource limits, FARS cannot currently conduct experiments that are extremely compute-intensive (e.g., large-scale pretraining), nor can it perform experiments that require direct human involvement, such as manual data annotation or expert human evaluation.
- Quality variance at scale. Even with internal review, some outputs may be incremental, uninteresting, or flawed in subtle ways.